Look-Alike (англ. «поиск похожих») — социально-демографический и поведенческий таргетинг, благодаря которому товар и/или услугу предлагают пользователям, по многим показателям похожим на существующих клиентов рекламодателя. В ходе кампании анализируется поведение посетителей сайта, на основе которого при помощи математического моделирования ищутся пользователи с похожими поведенческими характеристиками.
Гипотеза Look-Alike таргетинга такова: похожие между собой люди отличаются от всех остальных своим поведением в интернете, формируя общность со схожими интересами и потребностями — т.е. вашу идеальную целевую аудиторию с высоким потенциалом конверсии.
Механизм работы Look-Alike таргетинга
Look-Alike таргетинг обучаем — это происходит в процессе сбора данных о ранее посещавших сайт пользователях, совершавших целевые действия, либо по каким-либо причинам ушедших на этапе заказа. На основе всех этих действий (в том числе незавершённых) определяются уникальные паттерны поведения целевой аудитории. В дальнейшем это используется для технологий ретаргетинга, аукционных предложений и, конечно, показа рекламы тем пользователям, что ещё не знакомы с товаром или услугой, но вполне могли бы стать клиентами рекламодателя.
В российском сегменте сети Look-Alike таргетинг базируется на технологии «Крипта» от Яндекса, основанной на методе машинного обучения Матрикснет, технологии Look-Alike Audience Фейсбука и Google. Крипта была запущена ещё осенью 2011 года; она изучает поведение в интернете типичных представителей интернет-аудитории с теми или иными интересами. Look-Alike Audience Фейсбука запущена в 2012 году. Все данные собираются в обезличенном виде, касаются социально-демографических, поведенческих характеристик и формируются из открытых профилей в социальных сетях и на основе данных маркетинговых агентств. К примеру, собираются данные какие формулировки используют в запросах типичные представители групп пользователей, сколько запросов делают в течение сессии, в какое время суток выходят в интернет, какие сайты посещают и т.д.
О запуске таргетинга Look-Alike на Россию Яндекс объявил в сентябре 2013 года. По сути, это ещё более глубокий анализ поведенческих и социально-демографических факторов (числом более трёх сотен), значимость которых рассчитывается для конкретной аудитории. Всё это формирует формулу, по которой определяется соответствие пользователя какой-либо из имеющихся групп. Причём как формирование групп, так и сама формула постоянно проверяются и по необходимости корректируются.
Более того, для каждого пользователя возможность принадлежности к той или иной группе ежедневно пересчитывается, что позволяет учитывать малейшие изменения в интересах, потребностях и успевать реагировать на них. Для Look-Alike таргетинга порог соответствия группе достаточно высок — не менее 80%, и гибко настраивается в зависимости от особенностей аудитории, её размера, потребностей рекламодателя.
Помимо Яндекса подобный вид таргетинга пытаются внедрить и другие крупные игроки рынка. Главное ограничение — наличие действительно большой аудитории для адекватной оценки и выделения групп. За рубежом технология работает чуть дольше и оттого считается более профессионально настраиваемой. К примеру, в Google аналогичный инструмент носит название «Similar Users», и успешно работает на протяжении трёх лет. Также таргетинг Look-Alike использует Facebook.
В чём отличие Look-Alike от поведенческого и других видов таргетинга?
В теории все виды таргетинга так или иначе похожи: цель у них одна. Гораздо нагляднее показать отличия на конкретном примере: пользователь увлекается сноубордингом, при этом на одном из сайтов в разделе горнолыжной экипировки он находит нужный ему костюм. По законам классического ретаргетинга его будут «догонять» баннеры с горнолыжным оборудованием и экипировкой. Тогда как Look-Alike таргетинг на основе его поведенческих факторов и аналогичного поведения аудитории со сходным интересами обозначит пользователя как сноубордиста и определит в соответствующую группу для более точного рекламного контакта.
Наглядно изменение воронки продаж с помощью look-alike можно изобразить следующим образом:
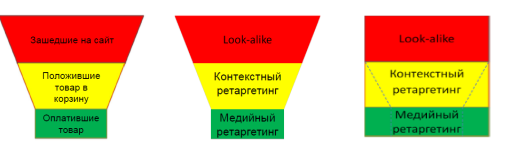
Применение и настройка Look-Alike таргетинга
Сегодня look-alike таргетинг применяется Яндексом для демонстрации медийной рекламы (баннеров и видеороликов) на площадках Новости, Почта, Диск, Афиша, Карты и Пробки, Маркет, Погода, Работа, Фотки, Словари, Авто, Телепрограмма, Расписания, Музыка и др., а также на сайтах партнёров Рекламной сети Яндекса.
Настройка рекламной кампании производится на странице интерфейса Яндекс.Метрики (разумеется, для этого на сайте должен быть установлен счётчик Яндекс.Метрики). Для этого в целях кампании рекламодатель задаёт ряд параметров для отслеживания аудитории. Например, отбор пользователей, положивших товар в корзину или открывших прайс-лист.
На основе заданных паттернов технология Крипта запускает поиск целевой аудитории и запоминает её характеристики, а механизм Look-alike вычисляет «похожую» аудиторию из тех, чьи модели поведения значительно походят на образцовые. По заявлениям компании, Яндекс планирует развивать look-alike таргетинг так, чтобы он автоматически проводил оптимизацию по конверсии уже запущенных рекламных кампаний, достигая наибольшей эффективности.
Расчет эффективности Look-Alike таргетинга
Уже сегодня о look-alike таргетинге говорится, что он помогает достичь рекордных показателей конверсии, заметно превышающих все прочие подходы к формированию целевых аудиторий. Теоретические выкладки применения look-alike таргетинга достигают прогноза увеличения с его помощью CTR в пять раз, конверсии — как минимум вдвое.
Впрочем, есть и открытые практические данные. В качестве примеров приводятся тестовые рекламные кампании KIA и Quelle. К примеру, у KIA в рамках одной из кампаний получилось увеличить количество отложенных конверсий почти в 2,5 раза.
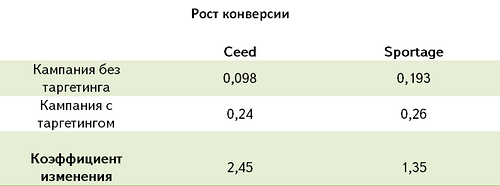
А у Quelle уже на четвёртой неделе размещения кликабельность баннеров увеличилась вдвое, а на седьмой неделе — практически в три раза!
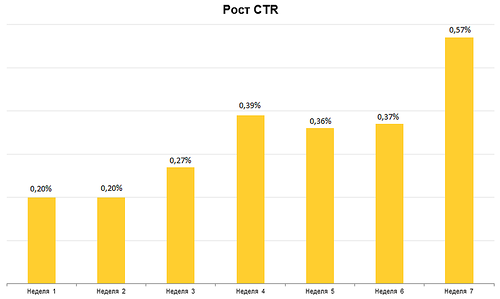
Впрочем, справедливости ради стоит отметить, что определенная заслуга в этом случае есть и у грамотного применения ручных настроек оптимизации кампании. В данном случае отчётливо видно, что на четвёртой неделе размещения первоначальный результат улучшается практически вдвое.
Перспективы
Эффективность рекламных кампаний растёт в том числе из-за изменения подхода к проведению кампаний у большинства рекламодателей. Если ранее модель проведения рекламной кампании в России подразумевала закупку «площадок» и «пакетов размещений», то сегодня приходит понимание в необходимости транслировать сообщение конкретной тонко очерченной целевой аудитории. Это и есть те самые «аудиторные закупки», базирующиеся на разного рода таргетингах. Самым современным и совершенным из которых сегодня можно назвать Look-Alike. Перелом в понимании рекламодателей произошёл именно с распространением RTB технологии, т.е. аукционной модели продажи рекламных мест.
Читайте также: Виды данных, Маркетинг на данных, Programmatic buying, Что такое RTB (Realtime Bidding)
Real-Time Bidding. Новая технология медиабаинга.



.jpg)